
Приветствую, дорогие сеошники!
Сегодня я решил разобрать очень важную тему. Мы будем говорить о том, как правильно составить семантическое ядро самому, разбить его по группам, а также очистить от лишних невалидных запросов. Если вы хотите более подробно узнать о том, что такое семантическое ядро, то милости прошу в материал, который доступен по приведенной ссылке.
- Семантическое ядро простыми словами
- Способы составления семантического ядра
- Key Collector
- Яндекс Вордстат
- Яндекс Вордстат + СловоЁБ
- Онлайн-сервисы
- Заказ у специалиста
- Стоит ли составлять семантику?
- Как правильно составить семантическое ядро по шагам?
- Сбор первичных ключей
- Парсинг базовых запросов при помощи СловоЁБа/Кей Коллектора
- Получение настоящей частотности
- Кластеризация запросов
- Поиск хвостов
- Заключение
Семантическое ядро простыми словами
Семантическое ядро – слова и словообразования, которые отождествляют тематику вашего сайта. Как правило, оно представляет собой сборник ключевиков, которые вы должны будете использовать при наполнении ресурса. Далее файл с этими ключами передается человеку, который занимается формированием технических заданий. Завершают эту цепочку копирайтеры, которые грамотно расставляют ключевые слова и фразы в статьях.
Для коммерческих сайтов данная цепочка также почти ничем не отличается, за тем лишь исключением, что ключевые слова и фразы используются в статичных элементах ресурса, описаниях товаров и услуг, а также прочих страницах с информацией.
В обоих случаях эти ключевики прописываются в мета-тегах сайта. Это одно из обязательных условий грамотного поискового продвижения веб-ресурса.
Наверное вы уже догадались, что эти слова и фразы зависят от того, что ищут пользователи в поисковых системах. Т. е. если в качестве примера взять запросы “купить красивый диван” и “магазины диванов”, то можно прикинуть, что по одному из них частота будет выше. Соответственно в интернет-магазине с диванами нужно будет указать ключ “Купить красивый диван”, чтобы поисковая система добавила в выдачу ваш ресурс по этому запросу.
Семантическое ядро или семантика – это список, состоящий из большого количества таких запросов, который, как правило, сгруппирован по определенному типу. Такое явление еще называют кластеризацией и почти во всех случаях специалисты прибегают к ее использованию. Это помогает не только составить грамотный план выписки текстов, но и определить, по каким именно типам поисковых запросов будет осуществляться продвижение.
Способы составления семантического ядра
Key Collector
Для составления семантики мы можем воспользоваться программами для создания СЯ. Какие-то из них делают почти всю работу за вас – их еще называют автоматическими. В каких-то сервисах придется больше работать самостоятельно.
Например, есть такая платная утилита Key Collector. Хотя в ней этот процесс почти полностью автоматизирован, необходимо знать, как настроить Key Collector. На выходе вам лишь остается немного прибраться в запросах, убрав оттуда наиболее бесполезные, что включает в себя запросы от роботов, спам и т. д. Стоимость такой программы составляет почти 2 000 рублей.
Яндекс Вордстат
Заниматься сбором семантики можно и с помощью сервиса от Яндекса – Вордстат. Им очень легко пользоваться, достаточно просто ввести ключевое слово, он выведет вам запросы, в которых присутствует данный ключ. Вместе с этим Wordstat покажет вам и похожие запросы, которые также могут быть интересны при продвижении.
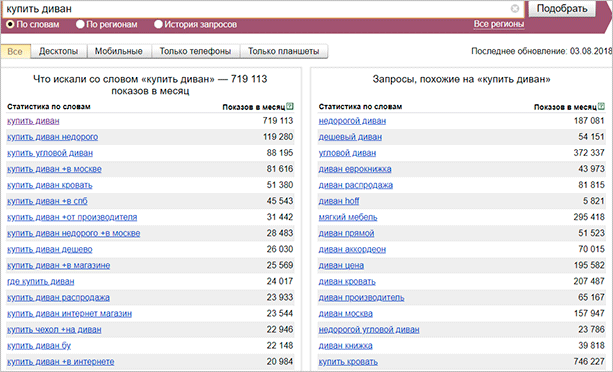
В этой статье с помощью Вордстата мы будем собирать первичные ключи, которые понадобятся нам для дальнейшего сбора семантического ядра. Но об этом позже, а пока я приведу вам еще несколько способов, с помощью которых можно собрать семантику.
Яндекс Вордстат + СловоЁБ
Программа с таким красочным названием является абсолютно бесплатным аналогом Key Collector. Естественно и функционала в нем чуть меньше, чем в коммерческом конкуренте, но для сбора семантического ядра под поисковое продвижение этого вполне хватит.
Если вам интересно, чем СловоЁБ отличается от Кей Коллектора, просто взгляните на эту табличку.
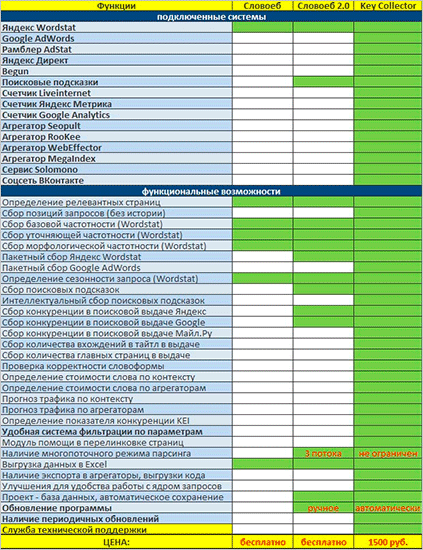
Безусловно, отличий здесь вагон и маленькая тележка. Однако для простого сбора ядра возможностей СловоЁБа вполне хватит.
Онлайн-сервисы
Итак, помимо вышеописанных вариантов, семантику можно сделать с помощью онлайн-сервисов. Если вы забьете запрос “Сбор семантики онлайн”, то поисковик выдаст вам большое количество всевозможных онлайн-инструментов. Они могут быть как хорошими, так и плохими. И, соответственно, как платными, так и бесплатными.
С помощью различных онлайн-сервисов можно еще узнать семантическое ядро конкурентов. Будьте уверены, что практически все компании занимаются проверкой данных своих потенциальных соперников.
Заказ у специалиста
Вы можете просто купить готовое решение у специалиста. Он все сделает, и на выходе вы получите целостный файлик со всеми запросами. Далее из него уже можно будет создать список статей с техническими заданиями к ним. Ну и отдать это все на растерзание копирайтерам. Но это уже вопрос делегирования обязанностей, его сегодня затрагивать мы не будем.
Стоит ли составлять семантику?
Если вы открыли эту статью, то вас, определенно, интересует и этот вопрос тоже. Сбор семантики кажется поначалу очень муторным и тяжелым делом. Причем пользователи не всегда понимают, зачем это вообще нужно.
Если мы говорим о блоге, причем созданном с целью заработка, то у авторов таких проектов возникает вполне резонный вопрос: где, собственно, брать вдохновение и про что вообще писать. Если у вас будет готовая таблица со всеми темами и ключевыми словами, то вы точно будете знать, о чем написать свой материал. Такой подход позволит не только не сбавлять темпа, но даже и увеличить, потому как вам не придется ломать голову над темой очередной статьи. Останется только выбрать из предложенного списка и решить для себя, как именно написать тот или иной материал.
Вместе с этим все ваши статьи (при условии грамотного написания текстов и соблюдения частотности ключей) будут неплохо вылетать в топ поисковых запросов, что обеспечит вам посещаемость, и это будет еще больше подогревать ваш интерес и мотивировать на новые свершения. Заманчиво же, правда? И все это благодаря одному единственному элементу – семантике, сбор которой у вас не займет много времени.
Если же речь идет о коммерческих сайтах (лендинги, интернет-магазины и пр.), то сбор семантического ядра просто обязателен. Вот серьезно, без этого вообще никак. Семантика нам понадобится как при наполнении ресурса контентом и мета-тегами, так и для контекстной рекламы, через которую мы будем продвигать бизнес.
Для сбора семантики под контекст одного СловоЁБа будет мало. Придется покупать его расширенную версию, именуемую Кей Коллектором. Программа имеет большое количество разных опций, предназначенных как раз для работы с разными контекстными сетями (Директ, Адвордс и т. д.)
Подводя итог, приходим к выводу, что составлять семантику определенно стоит. Это повышает качество продвижения вашего ресурса и позволяет вам на порядок лучше ориентироваться в потребностях пользователей при составлении контент-плана.
Как правильно составить семантическое ядро по шагам?
При подборе СЯ мы постараемся уложиться в пять шагов. Они будут включать в себя: поиск и подбор первичных ключевых слов, парсинг их в программе СловоЁБ или Кей Коллектор (сам буду использовать первый вариант), определение частотности для каждого запроса, кластеризация и сбор хвостов, т. е. дополнительных слов, которые содержатся в поисковом запросе.
Например: купить диваны черного цвета в Краснодаре онлайн, где жирным выделен наш ключ, а все что дальше – хвост. Если в наших статьях будут присутствовать не только основные запросы, но и хвосты к ним, то вполне вероятно, что эти самые материалы будут собирать посетителей с большего количества различных вариаций этих фраз.
Что же, давайте начнем составлять семантику по шагам.
Сбор первичных ключей
Для сбора первичных слов и фраз мы будем использовать Вордстат. Но перед этим нам нужно самостоятельно придумать, на какие темы мы будем писать статьи или же осуществлять продвижение, если речь идет о коммерческом типе сайтов. Для себя я выпишу такие темы рубрик:
- заработок,
- финансы,
- фриланс,
- копирайтинг,
- партнерки.
Думаю, что для примера 5 штук будет достаточно. В вашем случае этих тем может быть больше. При выборе первичных ключей для блога можно использовать названия рубрик, по которым в дальнейшем будет осуществляться написание текстов.
Теперь мы берем первое слово и забиваем его в Вордстат. Сервис выдает нам большое количество разных запросов с их частотностью, т. е. количеством обращений конкретно с такими словами в поисковик Яндекс. Вот так это выглядит.

Как видите, вариантов здесь предостаточно. Сервис выдал нам наиболее популярные запросы со словом заработок. В правой же части он показал похожие варианты, которые могут нам понравиться.
Казалось бы, можно на этом остановиться. Просто написать статьи с использованием ключей вроде “заработок в интернете” или “заработок без вложений” и ждать, когда десятки тысяч пользователей ринутся читать наш шедевр.
Но не все так просто, здесь представлены только высокочастотные ключевые фразы, продвигаясь по которым у нас не будет шанса попасть и в первую сотню сайтов. Выбрасывать их в помойку тоже не стоит, самое эффективное продвижение заключается в рациональном использовании всех типов ключевых слов и словосочетаний.
Теперь мы проделываем ровно то же самое по всем представленным первичным словам. А потом еще и по наиболее популярным вариациям, предоставленным самим сервисом.
После первого шага у нас на руках должен быть список из нескольких десятков самых вкусных, по нашему мнению и по мнению Вордстата, запросов. Старайтесь выбирать наиболее человеческие и правильные с точки зрения составления запросы. Я думаю, что проблем с этим возникнуть не должно.
Выглядеть это должно примерно так.

Парсинг базовых запросов при помощи СловоЁБа/Кей Коллектора
Теперь мы и переходим к самому интересному. С помощью СловоЁБа или Кей Коллектора мы должны спарсить все базовые запросы, сделав из них объемную сетку из самых различных вариаций. Иначе говоря, нам нужно получить все запросы, включающие в себя такие фразы или слова.
Создаем новый проект, используя кнопку в главном окне или в верхнем меню.
После того, как проект создан, нужно начать сбор семантики через Wordstat. Грубо говоря, программа сама подключится к Вордстату и соберет оттуда все необходимые данные. Для этого нам понадобится зарегистрировать новый аккаунт Яндекса, чтобы было не жалко, если его забанят, и вписать его данные в настройках. Сделать это нетрудно, тем более, что утилита сама выдает подсказки.
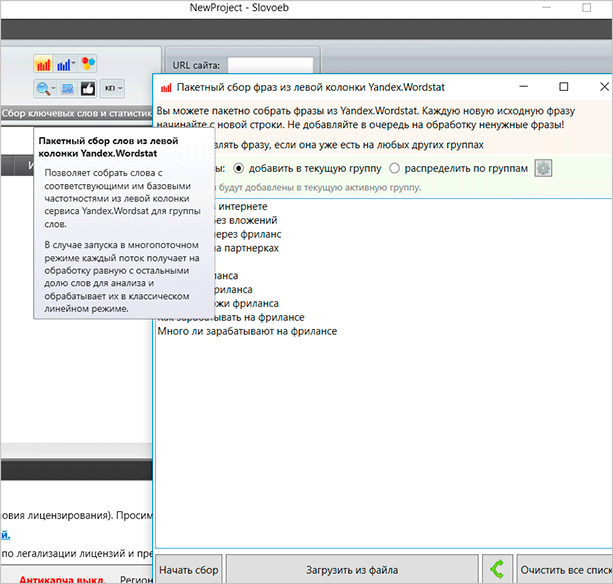
Обратите внимание, что для сбора мы используем левую колонку Вордстата. В ней будут все поисковые запросы, которые содержат этот ключ в прямом вхождении. Но мы также можем использовать и другой вариант – сбор из правой колонки, где есть “похожие” слова и фразы. Таким образом мы можем составить большое количество разносортных поисковых запросов, получив, ко всему прочему, еще и похожие.
Итак, вводим все ключи в поле выскочившего окна и после этого нажимаем на кнопку “Начать сбор”.
Процесс запустится, и программа начнет поиск запросов с содержанием нужных фраз. Само собой, чем больше будет этих самых фраз, тем больше будет запросов на выходе. Для примера я оставил один запрос “Заработок в интернете”, после чего запустил процесс. Вот такие данные мне выдала программа.
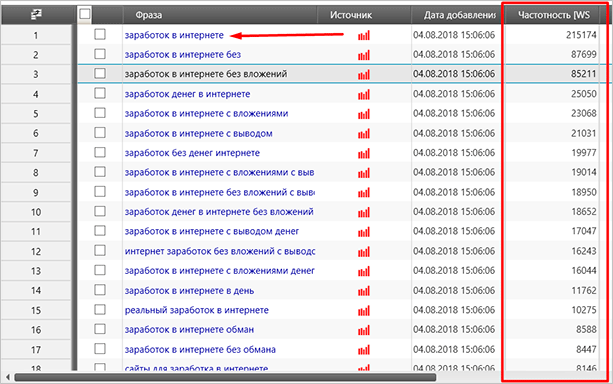
Как видите, со своей задачей она справилась, а я получил не только разносортные запросы, но и их частотность. Однако не спешите радоваться. Данные, которые я обвел красным прямоугольником, могут оказаться и вовсе бесполезными или неправильными. Такое явление еще называют грязная или базовая частотность.
Если вы будете ориентироваться на базовую частотность, то вполне возможно, что статьи, составленные с учетом, казалось бы, популярных запросов, не получат ни одного клика за несколько месяцев. По этой причине мы должны получить настоящие данные, для этого мы воспользуемся внутренним функционалом этой программы.
Получение настоящей частотности
Для получения настоящей частотности ключевых слов и фраз мы можем воспользоваться встроенным функционалом СловоЁБа или Кей Коллектора. Т. к. в этой статье мы рассматриваем работу именно с первой утилитой, я объясню все именно на ее примере. В Key Collector этот процесс почти ничем не отличается. Только возможно, что в новых версиях изменилось расположение элементов.
Но я уверен, что вы разберетесь. В СловоЁБе же мы просто находим вот такие кнопки.
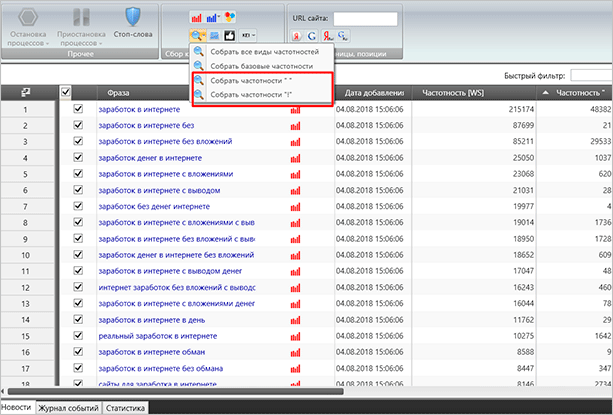
Частотность “ “ – вхождение только слов, которые находятся в кавычках. Окончания и порядок могут быть разными.
Частотность ! – точное вхождение ключа с фиксированным окончанием и порядком слов.
Чистка запросов позволит получить достоверные данные по частоте запросов, исходящих от пользователей Яндекса. Разницу между двумя столбцами вы можете видеть воочию. В ключе “заработок в интернете” чистая частота запросов почти в 5 раз меньше. В других словах она может быть еще более ощутимой, поэтому обязательно после каждого сбора семантики пользуйтесь инструментами для выявления более правильных показателей.
Когда процесс составления правильных данных будет завершен, вы можете воспользоваться быстрым фильтром (с регулярными выражениями) для поиска и удаления лишних запросов. Или вы можете сделать это вручную, просто прокрутив ползунок и найдя все варианты, которые не соответствуют какому-то определенному порогу.
В этом случае я рекомендую обращать внимание на запросы, которые могут принести нам трафик. Но не старайтесь лезть сразу в высокочастотные ключи, которые, как правило, использует очень огромное количество более раскрученных сайтов.
Конкурентность всех предложенных запросов мы, конечно, перепроверим далее. Однако ежу понятно, что если частота запроса составляет несколько десятков тысяч, то и конкурентов там будет очень много.
Надо исходить из соображений рационализма, о чем я уже говорил выше. Выбирайте ключи, по которым не слишком много запросов. Непопулярные отстойники, с частотой полтора запроса в месяц нам тоже не нужны.
Кластеризация запросов
Теперь нам предстоит разделить все наше семантическое ядро, а вернее ключи, которые в нем содержатся, на группы. Кластеризовать, в рамках этого материала, я буду как раз по частотности. Это наиболее популярный вариант, который используется почти повсеместно.
Все слова и фразы мы можем разделить на высокочастотные, среднечастотные, низкочастотные и микронизкочастотные. Объяснять, по какому принципу происходит группировка, думаю, не нужно. Однако, обозначить примерные диапазоны необходимо.
Сразу скажу, что сколько людей, столько и мнений. Иногда они расходятся, считать мой вариант за абсолютную истину не стоит. Вполне возможно, что у других специалистов значения будут отличаться в большую или меньшую сторону.
- ВЧ – свыше 10 000 запросов в месяц,
- СЧ – от 1 000 до 10 000,
- НЧ – до 1 000,
- МНЧ – меньше 100.
Цифры крайне субъективны и примерны, взяты из общепринятых данных, которые я когда-то получил опытным путем. Но стоит сказать, что этот вариант я видел часто.
Принцип кластеризации по частоте будет выглядеть как разбивка всех запросов по группам, исходя из количества поисковых обращений пользователей. Их мы уже получили на предыдущем шаге, теперь нам остается распределить запросы по этим группам.
Здесь же можно ввести еще несколько групп, уже исходя не из частотности запросов, а из конкурентности, то есть количества сайтов, которые уже осуществляют продвижение по ним.
Есть высококонкурентные, среднеконкурентные и низкоконкурентные запросы. Мы можем разгруппировать все данные и по такому типу, что даже будет предпочтительнее. Для более эффективного продвижения нашего сайта мы должны подобрать запросы с наибольшей частотой и наименьшей конкуренцией. Это, конечно, в идеале.
Для кластеризации запросов можно пользоваться как автоматическими инструментами (онлайн-сервисы), так и своими собственными ручками.
Если делать это вручную, то можно в прямом смысле сойти с ума. И дабы не ломать свою психику, я бы советовал вам воспользоваться автоматическими сервисами для разбивки всех ключевых слов по группам.
Таких сервисов в интернете не так много. Более-менее хороших еще меньше, однако слава об одном из достаточно приемлемых сервисов для кластеризации семантики ходит по Рунету вот уже который год. Я говорю о сервисе Мутаген, с помощью которого мы и будем воспроизводить все вышеописанные действия.
Данный онлайн-инструмент платный, но здесь есть возможность и бесплатного использования с некоторыми ограничениями. Не более 10 проверок в сутки.
Проблем с использованием Мутагена быть не должно. Интерфейс там интуитивно понятный, на русском языке. Там же есть небольшое ЧаВо, в котором объясняются основы работы с этим сервисом.
Здесь же скажу, что для более быстрой кластеризации нужно пользоваться массовой проверкой. Не будем же мы тысячи запросов проверять по одному. Для этого придется зарегистрироваться на сервисе и только после этого раздел массовой проверки станет доступен.
Потом останется просто скопировать все ключи из СловоЁБа, ну и по завершению всех процессов изучить все показатели конкурентности, а далее и сгруппировать их.
Поиск хвостов
Напоследок мы должны взять все самые вкусные ключи, после чего попробовать поискать хвосты. Просто вбиваем нужный запрос в Яндекс, после чего он выдаст их нам сам.

Как видите, здесь их не так много. Казалось бы, зачем вообще проверять и парсить хвосты с запросов. Неужто умный Яндекс сам не закинет наш ресурс в выдачу по запросам с хвостами? Может быть и закинет, однако, если где-то на вашем ресурсе будут проскакивать материалы вот с такими хвостами, то намного более вероятно именно ваш сайт будет в топе выдачи по этим запросам.
Продвижение с использованием запросов с хвостом особенно актуально для молодых сайтов. Траста у таких ресурсов еще нет, а вот если где-то в статье будет ключ в прямом вхождении, то вероятнее всего Яндекс кинет в топ даже ресурс без траста. Яше важно, чтобы каждый пользователь получал именно то, зачем он пришел в поисковик. Поэтому стоит пользоваться этим и добавить в свое семантическое ядро запросы с хвостами.
Собирать хвосты, к большому сожалению, придется вручную. Но вам не стоит пытаться парсить хвосты для всех тысяч ключей. Делайте это избирательно, с учетом понимания того, что может быть действительно интересно вашим посетителям.
Заключение
Как видите, собрать семантическое ядро можно всего за 5 шагов. Конечно, в этой инструкции представлен базовый вариант, который поможет вам познать азы и сделать самую простую семантику. Для более серьезных проектов понадобится соответствующий подход. Например, при кластеризации ключевиков вам придется делить их не только на ВЧ и НЧ, или ВК и НК, но и на коммерческие и некоммерческие. Или даже на группы с учетом региональности.
Все это будет непременно занимать время, но если вы самостоятельно будете работать над семантикой, собирать ее и видеть, как вообще обстоят дела на рынке поисковых систем, то по прошествии времени к вам постепенно будет приходить и понимание. Вы будете находить все новые инструменты для различных процессов, сможете делать сбор семантики и ее группировку чисто на одном дыхании. Конечно же, при условии, что вам это будет интересно.
Если вы сами не хотите разбираться со всем этим, то всегда можно заказать сбор семантического ядра у фрилансера или какой-нибудь студии. В интернете полно различных контор, которые готовы спарсить все данные и просто предоставить вам Excel-файлик. Цена может быть разной. Но я уверен, что если захотеть, то можно найти хорошего специалиста.Кстати говоря, если вам что-то непонятно из этой статьи и вы никак не можете разобраться со сбором семантического ядра, то должен уведомить, что на курсе Василия Блинова “Как создать блог” этот вопрос также будет обсуждаться. Возможно вам стоит пройти обучение и получить все необходимые знания.
До встречи в следующем обзоре.