
Дубли – это страницы сайта с одинаковым содержимым, они могут полностью повторять контент друг друга или частично. Часто они становятся причиной низких позиций ресурса. Мы хотим рассказать, почему могут возникать дубли и как от них избавится.
Полные дубликаты могут возникать, когда страница доступна под несколькими адресами, то есть не выбрано главное зеркало или не настроен 404 редирект. Часто их автоматически создает CMS в процессе разработки.
Частичные дубли часто получаются в результате ошибки разработчика или из-за особенностей CMS. Это могут быть страницы пагинации и сортировок с разными URL или ошибочно открытые для индексации служебные страницы.

В чем опасность
По сути, страницы одного сайта начинают соперничать друг с другом. Google и Яндекс не хранят в собственной базе несколько идентичных страниц, а выбирают только одну, наиболее релевантную. Они могут выбрать копию нужной вам страницы, в результате чего, позиции резко проседают. Из-за дубликатов страдают поведенческие факторы и естественный ссылочный вес, становится труднее собирать статистические данные.
Если дубликатов много, то поисковик может попросту не успеть проиндексировать их полностью. При этом следующей индексации придется ждать дольше, так как поисковые боты реже переходят на ресурс, где контент повторяется. А это также значительно замедляет продвижение.
Как найти дубли страниц
Сервисы для вебмастеров
Существует несколько способов. Наиболее простой – воспользоваться сервисами Google Search Console или «Яндекс.Вебмастер». Распознать дубликаты проще всего по повторяющимся метатегам title и description.
Для этого в панели инструментов Search Console перейдите в раздел «Оптимизация HTML» пункт «Повторяющееся метаописание», где будет указано количество таких страниц, а также их URL.
В вебмастере Яндекса, страницы с одинаковым метаописанием можно найти в разделе «Индексирование», а именно «Вид в поиске», где необходимо выделить исключенные страницы и выбрать категорию «Дубли».
Существует также много других сервисов для подобных задач, например Netpeak Spider или Screaming Frog. С их помощью можно получить полный список адресов страниц и автоматически выделить среди них те, у которых совпадают метатеги.
При помощи операторов ПС
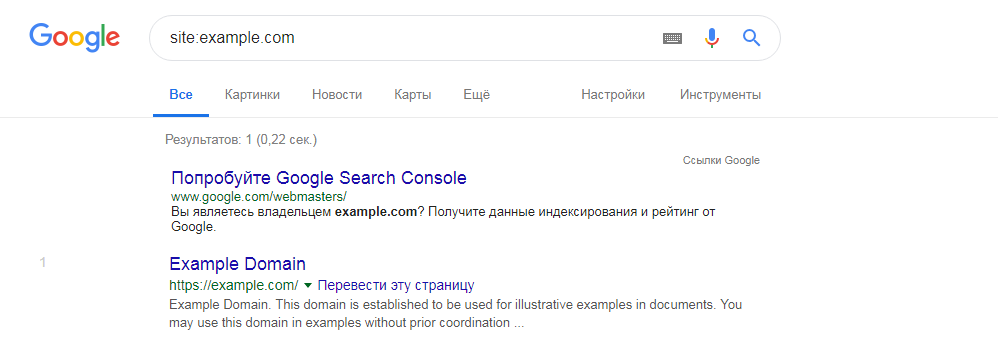
При помощи оператора site: для Google или host: для Яндекса, можно вручную искать повторяющийся контент на страницах поисковой выдачи. Для этого введите в поисковую строку оператор перед адресом вашего сайта, а дальше нужный отрывок текста в кавычках (site:address.com””). Таким образом вы сможете отыскать не только полные, но и частичные дубли.
Если использовать оператор с адресом без текста, в выдаче вы увидите все проиндексированные страницы собственного ресурса. По одинаковым заголовком можно легко определить копии.
Как исправить
Удалить вручную. Подходит для борьбы с полными копиями, которые возникли в результате ошибок. Для этого достаточно найти их URL и удалить при помощи CMS.
Закрыть от индексации. Для этого в файле robot.txt следует использовать директиву disallow. Таким образом вы сможете закрыть индексацию указанных типов страниц.
При помощи тега rel=canonical. Позволяет решить проблему с разными адресами страниц пагинации и др.
Настроить редирект 301. Редирект перенаправляет со всех похожих URL на один основной.
Как борются с дубликатами в Elit-Web
Когда к нам на продвижение приходят сайты, разработанные не у нас, технические ошибки, в том числе дубли, – один из первых пунктов проверки.
Многим не удается найти все копии страниц. Автоматический поиск осуществляется исключительно по метатегам. А чтобы искать при помощи контента, необходимо знать, какой именно текст может повторятся. Потому даже после работ по внутренней оптимизации, могут остаться ошибки.
Мы устраняем ошибки, используя все доступные методы проверки. Также наши специалисты ориентируются на саму специфику CMS и работ, проведенных на сайте, чтобы удостоверится, что на сайте не осталось дублей. А потому если у вас возникли проблемы с продвижением, мы уверены, что сможем помочь.